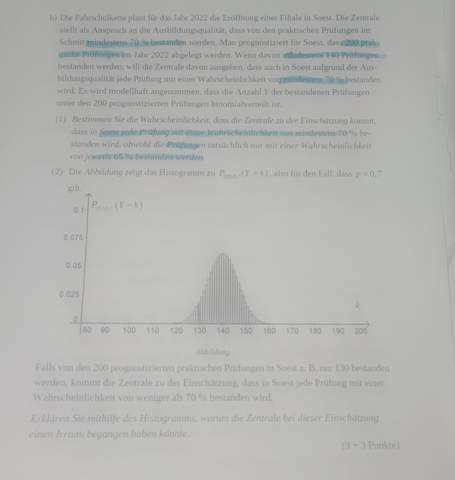
Hallo zusammen,
Es existiert eine Methode, die als Systemisches Konsensieren bezeichnet wird. Die Entscheidungsfindung erfolgt auf dieser Grundlage folgendermaßen. Wenn es zwei Lösungsvorschläge (A und B) gibt, müssen die Gruppenmitglieder jeweils ihren Widerstand für die beiden Lösungsvorschläge angeben. Dabei ist es möglich, eine Punktzahl von 0 bis 10 zu geben. 0 stellt keinen Widerstand dar, 10 stellt einen maximalen Widerstand dar. Die Widerstandswerte der Gruppenmitglieder werden für jede Lösung zusammengerechnet. Der Lösungsvorschlag mit dem geringsten Gesamtwiderstandswert wird daraufhin ausgewählt.
Hier ein Beispiel:
Der Gesamtwiderstandswert des Lösungsvorschlags A beträgt 52, während der Wert des Lösungsvorschlags B 48 beträgt. Daher wird nach der Methode des Systemischen Konsensierens die Entscheidung für B getroffen. Jetzt frage ich mich, ob dies überhaupt demokratisch sein kann. Aufgrund der Tatsache, dass die Mehrheit (6 Personen) für die Lösung A ist, aber dennoch sich nach dem Ansatz für B entschieden wird. Was denkt ihr? Ist es korrekt wenn man sagt dass es undemokratisch ist, wie das Beispiel zeigt? Vielen Dank im Voraus :)